One of the great features of Simple.Data is that it interprets method and property names at runtime and maps them to your underlying data-store using the convention-based approach. It also allows you to identify schema, table and column names using an indexer syntax detailed here.
The convention is as follows.
All method calls start with a reference to the database which you generate by calling
one of the four Database.Open() methods.
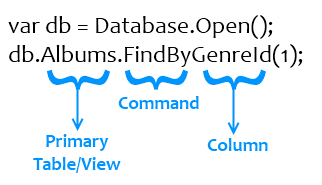
The primary table or view in your query is specified next. When the database is eventually queried for data (Simple.Data is late-binding by default), it first checks to see if the given name exists as either a table or a view. If it doesn’t, it checks to see whether the given name is singular or plural and then checks whether the plural or singular form of the word is the correct name instead.
In the example above, the name of the table targeted is actually
Album rather than Albums. Simple.Data first
retrieves a list of tables and views from the INFORMATION_SCHEMA.TABLES
system table and attempts to find the target name within them.
It tries an exact match first (Albums)
Then it strips out all non-alphanumeric characters and tries a case-insensitive match on what’s left (albums)
Then a pluralized version if the string ‘is not a plural’ (Albums)
Finally a singularized version if the string ‘is a plural’ (Album)
You can also specify a database schema to identify the correct table or view. For
example, Album is a table in the dbo
schema.
db.dbo.Albums.FindByGenreId(1);
The general form of this syntax is
DatabaseReference.[schema_name.]Table_or_View.method();
Simple.Data contains twenty methods for data retrieval and manipulation (see list here). One of those methods is specified next.
If you choose to use one of the eight methods ending in “By”, for example FindBy(), you must also specify at least one column in the primary table or view by which to filter your search along with a value for it. For example,
db.Albums.FindByGenreId(1);
will resolve into a query searching for all rows in the Album table where GenreId is set to 1.
Additional criteria can be added by concatenating more column names to the end of the method name, separated by “And”, with the column values set in the arguments to the method. For example,
db.Albums.FindByGenreIdAndArtistId(1,1);

So, for example, Albums.GenreId will match all of:
And other such variations.
The fluid naming convention for schemas, tables and columns is great if you know what you’ll need to query at build time.
However it does not work for situations where what to query is determined at runtime. For that you can use the indexer syntax and
will need to avoid using the FindBy* and FindAllBy* methods.
The general form of this syntax is
DatabaseReference["SchemaName"]["Table_or_View"]["ColumnName"]
As above, if your database has only one schema, you can omit the schema name part. You can also chain method calls on to the end as demonstrated above. For example,
db.dbo.Albums.FindByGenreId(1);
can also be written as:
db["dbo"]["Albums"].FindByGenreId(1);
db.dbo["Albums"].FindByGenreId(1);
db["dbo"].Albums.FindByGenreId(1);
db["Albums"].FindByGenreId(1); //if dbo is only schema
You can find further examples of indexer sytax in the page on Column Selection and in the Sample Code Project
When trying to match method and property names with your underlying data-store, Simple.Data will strip out all non-alphanumeric characters and try a case-insensitive match on what's left. There are times when this might not be ideal, such as having tables or columns with similar names:
IsGenerated Is_Generated
With the non-alphanumeric characters removed, this leads to duplicate columns names: isgenerated.
To work around these scenarios, you simply need to override the regular express that Simple.Data uses to remove non-alphanumeric characters to include the characters which distinguish your columns from being duplicates. In the example above, we need to tell Simple.Data to include the underscore character to avoid the naming conflicts with a one-time call to a static method:
Simple.Data.Extensions.HomogenizeEx.SetRegularExpression(new Regex("[^a-z0-9_]"));
Now that we've told Simple.Data to include the underscore character, it now separates the distinct names correctly: isgenerated and is_generated.
The default regular expression that Simple.Data uses to find valid characters in names is new Regex("[^a-z0-9]").